Процес
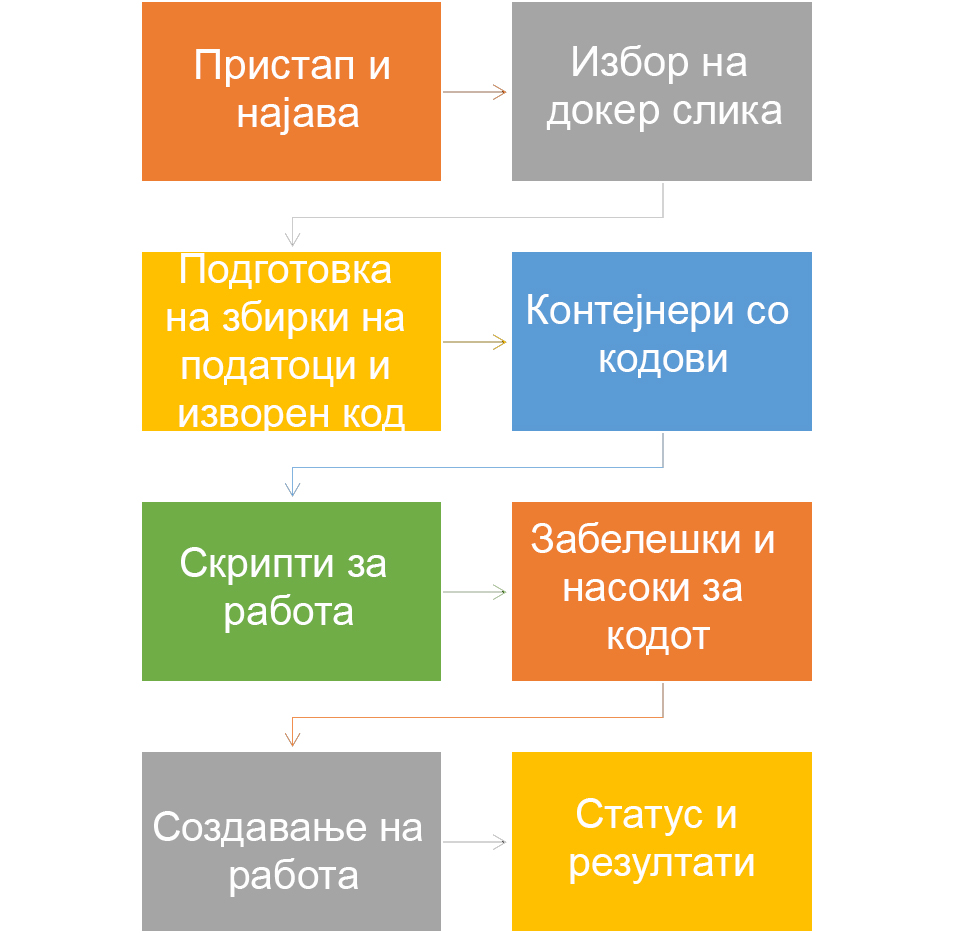
Пристап и најава
- Генерирајте SSH клуч или користете го постоечкиот SSH клуч
- Најавете се на https://osc-lab.finki.ukim.mk/ и во вашиот профил додадете го вашиот SSH клуч
- Ќе добиете информации за корисничкото име создадено на кластерот GPGPU.
- Поврзете се со услугата EDUVPN за OpenLab
- Користете SSH клиент за да се најавите на адресата 10.10.65.6 (преден јазол на кластерот GPU) користејќи клуч ssh
- ssh -i <PATH_TO_PRIVATE_KEY> USERNAME@10.10.65.6
Избор на docker image
Најлесен начин да се изврши кодот на GPGPU е користење на докеризирана верзија на софтверот/библиотеките на кои се базира вашиот код. Ние користиме каталог NVIDIA NGC како извор на докер слики со претходно инсталиран софтвер/библиотеки/модели што ги користиме во нашиот код.
На пример, ако нашиот код тренира модел користејќи библиотека базирана на pytorch, можеме да ја користиме следнава докер-слика (замени XX.XX со потребната верзија достапна на NGC):
docker image pull nvcr.io/nvidia/pytorch:XX.XX-py3
Пр.:
docker image pull nvcr.io/nvidia/pytorch:23.05-py3
Подготовка на кодови и сетови на податоци
Во вашиот домашен директориум /home/hpc/users/ креирајте директориум со код кој ќе ги содржи кодот, податоците и датотеката за задачата (job.sh).
Директориумот за код, податоци и резултати ќе биде поврзан со вашиот контејнер за singularity
—JOB_FOLDER_NAME
—Dockerfile (**опционално)
— job.sh
—code
—data
—results
— …
Следниве чекори треба да се извршат од овој директориум
Создавање на контејнери за кодови
Singularity е платформа за контејнеризација која овозможува водење контејнери кои содржат различни парчиња софтвер на пренослив и репродуктивен начин. Singularity како платформа беше создадена за да овозможи извршување на сложени апликации на HPC системи преку фаворизирање на интеграцијата наместо изолацијата и со тоа олеснување на користењето на единиците на графичкиот процесор, системите за податоци на кластери итн.
Контејнерите кои се креирани во платформата за сингуларност се датотеки со екстензија .sif.
Создавање на контејнери за кодови – чекор прв
Ако треба да инсталирате дополнителни библиотеки или пакети (покрај она што е инсталирано на сликата што ја преземате од каталогот NVIDIA NGC), треба да креирате Dockerfile во вашиот директориум за експерименти.
Содржината на Dockerfile треба да биде како што следува:
FROM {NVIDIA_NGC_IMAGE}
RUN {install commands here e.g. pip install pytorch-geometric}
Откако ќе бидеме подготвени со Dockerfile, треба да создадеме нов image
docker build -t DOCKER_IMAGE_TAG .
Пр.
docker build -t pyg .
Создавање на контејнери за кодови – чекор втор
Ако не треба да инсталирате дополнителни библиотеки или пакети (освен она што е инсталирано на сликата што ќе ја преземете од каталогот NVIDIA NGC), продолжувате директно со креирање на сликата sif со следните команди:
docker save DOCKER_IMAGE_NAME -o ARCHIVED_DOCKER_IMAGE_NAME.tar
singularity build SIF_IMAGE_NAME.sif docker-archive://ARCHIVED_DOCKER_IMAGE_NAME.tar
DOCKER_IMAGE_NAME може да биде името на сликата преземена од NVIDIA NGC или името на сликата создадена од вас со извршување на датотеката Dockerfile.
ARCHIVED_DOCKER_IMAGE_NAME и SIF_IMAGE_NAME се избрани од вас и може да се однесуваат на библиотеката/моделот што го користите.
Создавање скрипта за работа
Во истиот директориум што се однесува на вашиот експеримент/работа, додадете shell скрипта со име job.sh.
Содржината на скриптата:
#SBATCH --job-name CudaJob
#SBATCH --output result.out ## filename of the output; the %j is equivalent to jobID; default is slurm-[jobID].out
#SBATCH --partition=openlab-queue ## the partitions to run in (comma seperated)
#SBATCH --ntasks=1 ## number of tasks (analyses) to run
#SBATCH --gres=gpu:3 # select node with v100 GPU
##SBATCH --mem-per-gpu=100M # Memory allocated for the job
##SBATCH --time=0-00:10:00 ## time for analysis (day-hour:min:sec)
# parse out number of GPUs and CPU cores assigned to your job
env | grep -i slurm
N_GPUS=`echo $SLURM_JOB_GPUS | tr "," " " | wc -w`
N_CORES=${SLURM_NTASKS}
#export SINGULARITYENV_CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES}
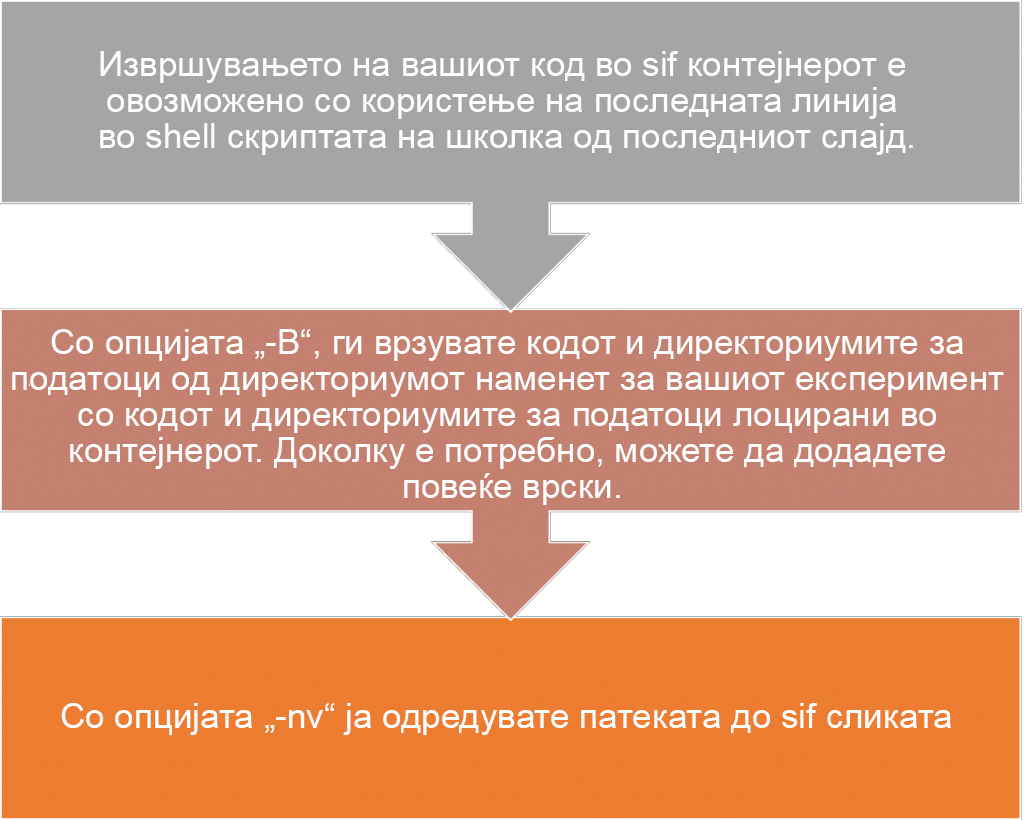
singularity exec \
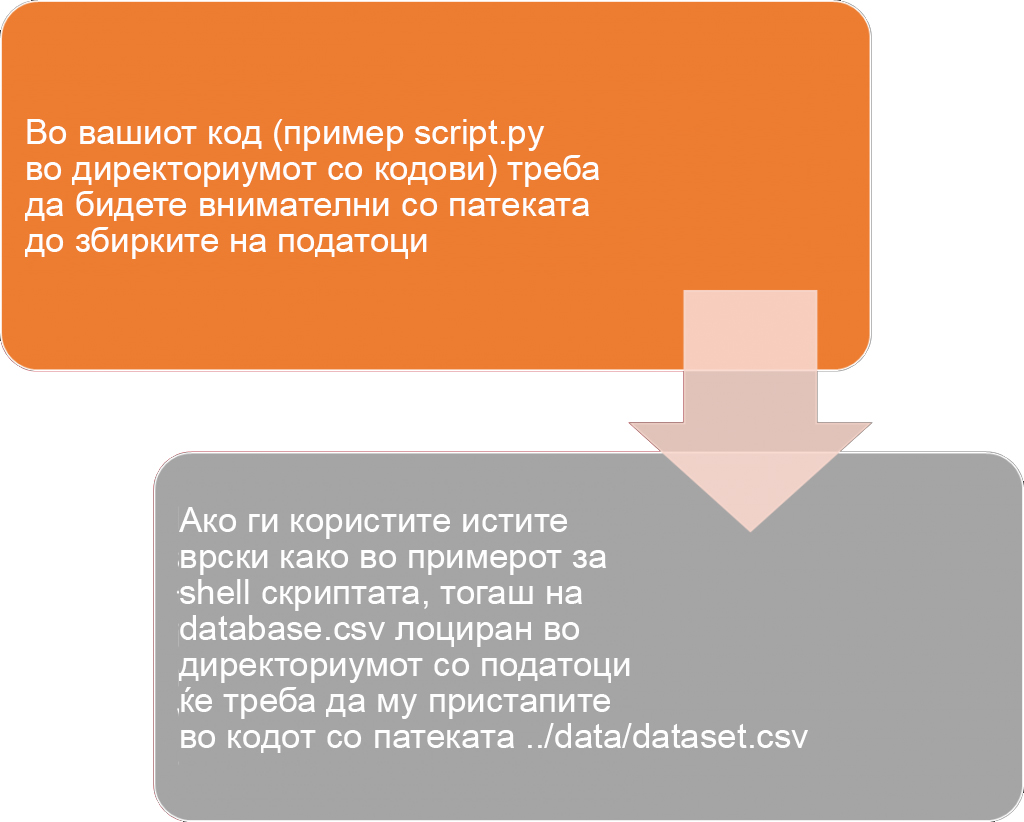
-B ./code:/code \
-B ./data:/data \
--nv SIF_IMAGE_NAME.sif \
python3 code/PYTHON_SCRIPT_NAME.pyСоздавање на работа
Забелешки и насоки за кодот
Извршување на работа
Работите се извршуваат целосно идентично на веќе постоечката лоша (инструкции достапни овде).
Командата sbatch ја поставува задачата во редица.
Работен статус
- squeue (проверка на статусот на сите работите во редица)
- sinfo (проверка на статусот на јазлите и партициите во кластерот)
- scancel (запрете ја задачата (или повеќе задачи), со дефинирање на id)
- sacct (информации за завршените и тековните задачи, како и за корисниците кои ги започнале)
- sstat (податоци за тековните задачи и кориснички информации)